Дисперсионный анализ может быть. Курсовая работа: Дисперсионный анализ. Видим, что полученная зависимость не характерна для среднего и среднего профессионального образования. В остальных случаях она справедлива
Стат. группировка – это процесс образования однородных групп на основе расчленения стат. совокупности на части, или объединение изучаемых единиц в частные совокупности по существенным для них признакам.
Статистические группировки делятся на :
1) типологическая группировка – разделение исследуемой качественно разнородной совокупности на классы, соц.–эк. типы, однородные группы единиц (пример: группировка промышленных предприятий по формам собственности);
2) структурная группировка – происходит разделение однородной совок-ти на группы, характеризующие ее стр-ру по какому–либо варьирующему признаку;
3) аналитическая группировка – выявляет взаимосвязи м/у изучаемыми явлениями и их признаками.
Всю совок-ть признаков можно разделить на 2 группы : факторные и результативные . Факторными называются признаки, под воздействием которых меняются результативные признаки. С возрастанием значения факторного признака возрастает или убывает среднее значение результативного.
Особенности аналитической группировки: 1) в основу группировки кладется факторный признак; 2) каждая выделенная группа характеризуется средними значениями результативного признака.
9.Принципы выбора группировочного признака. Образование групп и интервалов группировки.
Группировка – это процесс образования однородных групп на основе расчленения статистической совокупности на части или объединение изучаемых единиц в частные совокупности по существенным для них признакам.
Классификация группировочных признаков :
По форме выражения: атрибутивные (профессия, образование); количественные (число работников, величина дохода): дискретные (целые числа), непрерывные (дробные);
По характеру колеблемости: альтернативные; имеющие множество количественных знаний (размер торговых площадей, фонд оплаты труда)
По роли, которые играют признаки во взаимосвязи изучаемых явлений: факторные (воздействующие на другие признаки); результативные (испытывают на себе влияние других). Выбор интервалов группировки: основным требованием является выбор такого числа групп и величины интервала, которые позволяют более равномерно распределить единицы совокупности по группам и достичь при этом их представительности и качественной однородности.
Представительность выборки (репрезентативность) это когда состав отобранной для исследования части единиц совокупности наиболее полно отображает состав всей изучаемой совокупности. Интервалы бывают равнее и неравные. Величина равного интервала: i= , где n-кол-во групп. Неравные интервалы устанавливаются в случаях, когда колеблемость признака осуществляется неравномерно и в больших пределах. Интервалы бывают открытые (с одной границей – верхней или нижней); закрытые, имеющие нижние и верхние границы.
10. Статистические ряды распределения.
Статистические ряды распределения – это упорядоченное расположение единиц совок-ти на группы по группиров признаку. Виды : 1.атрибутивный – это ряд, построенный по качественным признакам; 2.вариационный – образован по количественному признаку. Различают дискретные (признак принимает только целые значения) и интервальные (признак принимает в определенном интервале любые значения) вариационные ряды распределения. Вариационные ряды состоят из двух элементов: частоты и варианты. Варианта - отдельное значение варьируемого признака, которое он принимает в ряду распределения. Частота – это численность отдельных вариант или каждой группы вариационного ряда (в %). Плотность распределения – это отношение числа единиц совокупности к ширине интервала. Анализ рядов распределения можно проводить на основе их графического изображения. Полигон – ломаная кривая, строится на основе прямоугольной системы координат, когда по оси Х откладываются значения признака, а по оси У – частоты. Кумулята – ломаная кривая, строящаяся на основе прямоугольной системы координат, когда по оси Х откладываются значения признака, а по оси У – накопленные частоты (число значений, которые попали в интервал и все предшествующие).
Группировкой называется разбиение общей совокупности единиц объекта наблю-дения по одному или нескольким существенным признакам на однородные группы, раз-личающиеся между собой в количественном и качественном отношении и позволяющие выделить социально-экономические типы, изучить структуру совокупности и проанализи-ровать связи между отдельными признаками. Группировки являются важнейшим стати-стическим методом обобщения статистических данных, основой для правильного исчис-ления статистических показателей.
С помощью метода группировок решаются следующие задачи:
Выделение социально-экономических типов явлений;
Изучение структуры явления и структурных сдвигов, происходящих в нем;
Выявление взаимосвязи и взаимозависимости между явлениями.
В соответствии с познавательными задачами, решаемыми в ходе построения стати-стических группировок, различают следующие их виды: типологические, структурные, аналитические.
Типологическая группировка - это разбиение разнородной совокупности единиц наблюдения на отдельные качественно однородные группы и выявление на этой основе социально-экономических типов явлений. При построении группировки этого вида ос-новное внимание должно быть уделено идентификации типов и выбору группировочного признака. Решение вопроса об основании группировки должно осуществляться на основе анализа сущности изучаемого социально-экономического явления.
Структурной называется группировка, которая предназначена для изучения соста-ва однородной совокупности по какому-либо варьирующему признаку, а также структуры и структурных сдвигов, происходящих в нем.
Группировка, выявляющая взаимосвязи между изучаемыми явлениями и призна-ками, их характеризующими, называется аналитической группировкой.
В статистике при изучении связей социально-экономических явлений признаки не-обходимо делить на факторные и результативные.
Факторными называются признаки, под воздействием которых изменяются дру-гие результативные признаки. Взаимосвязь проявляется в том, что с возрастанием или убыванием значения факторного признака систематически возрастает или убывает значе-ние признака результативного и наоборот.
Особенностями построения аналитической группировки являются:
Единицы статистической совокупности группируются по факторному признаку;
Каждая выделенная группа характеризуется средними величинами результативного признака.
По способу построения группировки бывают простые и комбинационные.
Простой называется группировка, в которой группы образованы только по одному признаку.
Комбинационной называется группировка, в которой разбиение совокупности на группы производится по двум и более признакам, взятым в сочетании (комбинации).
Сначала группы формируются по одному признаку, затем группы делятся на под-группы по другому признаку, а эти в свою очередь делятся по третьему и так далее. Таким образом, комбинационные группировки дают возможность изучить единицы совокупно-сти одновременно по нескольким взаимосвязанным признакам.
При построении комбинационной группировки возникает вопрос о последователь-ности разбиения единиц объекта по признакам. Как правило, рекомендуется сначала про-изводить группировку по атрибутивным признакам, значения которых имеют ярко выра-женные качественные различия.
Принципы построения статистических группировок и классификаций.
Построение статистических группировок осуществляется по следующим этапам:
1. Определение группировочного признака.
2. Определение числа групп.
3. Расчет ширины интервала группировки.
4. Определение признаков, которые в комбинации друг с другом будут характери-зовать каждую выделенную группу.
Построение группировки начинается с определения группировочного признака.
Группировочным признаком называется признак, по которому проводится раз-биение единиц совокупности на отдельные группы. От правильного выбора группировочного признака зависят выводы статистического исследования. В качестве основания груп-пировки необходимо использовать существенные, теоретически обоснованные признаки.
В основание группировки могут быть положены как количественные, так и качест-венные признаки. Количественные признаки - это признаки, которые имеют числовое выражение (объем выпускаемой продукции, возраст человека, доход сотрудника фирмы и т. д.). Качественные признаки отражают состояние единицы совокупности (пол, отрас-левая принадлежность предприятия, форма собственности фирмы и т.д.).
После того, как определено основание группировки, следует решить вопрос о количе-стве групп, на которые необходимо разбить исследуемую совокупность единиц наблюдения.
Число групп зависит от задач исследования и вида показателя, положенного в ос-нование группировки, объема изучаемой совокупности и степени вариации признака. Вид показателя особенно существенен при анализе качественных признаков. Так, например, группировка сотрудников фирмы по полу учитывает только две градации: «мужской» и «женский».
В случае группировки единиц наблюдения по количественному признаку особое внимание необходимо обратить на число единиц исследуемого объекта, объем совокупно-сти и степень колеблемости группировочного признака.
При небольшом объеме совокупности (n<50) не следует образовывать большого количества групп, так как группы будут включать недостаточное число единиц объекта. Показатели, рассчитанные для таких групп, не будут представительными и не позволят получить адекватную характеристику исследуемого явления.
Часто группировка по количественному признаку имеет задачу отразить распреде-ление единиц совокупности по этому признаку. В этом случае количество групп зависит, в первую очередь, от степени колеблемости группировочного признака: чем больше его ко-леблемость, тем больше можно образовать групп. Поэтому при определении числа групп необходимо принять во внимание размах вариации признака (R), который позволяет оце-нить вариацию признака между крайними значениями признака - максимальным (Хmах) и минимальным (Xmin) и определяется по следующей формуле:
R = Хmах - Xmin
Чем больше размах вариации признака, положенного в основание группировки, тем, как правило, может быть образовано большее число групп. При этом может возникнуть проблема получения пустых групп, т.е. групп, не содержащих ни одной единицы на-блюдения.
Построение большого числа групп позволит, с одной стороны, точнее воспроизве-сти характер исследуемого объекта. Однако, с другой стороны, слишком большое число групп затрудняет выявление закономерностей при исследовании социально-экономиче-ских явлений и процессов. Поэтому в каждом конкретном случае при определении числа групп следует исходить не только из степени колеблемости признака, но и из особенно-стей объекта и показателей, его характеризующих, а также цели исследования.
Определение числа групп можно осуществить несколькими способами. Формаль-но-математический способ предполагает использование формулы Стерджесса :
n = 1 + 3,322 × lgN, (3.1)
n - число групп;
N - число единиц совокупности.
Согласно этой формуле выбор числа групп зависит только от объема изучаемой совокупности.
Применение данной формулы дает хорошие результаты в том случае, если сово-купность состоит из большого числа единиц наблюдения (n>50).
Другой способ определения числа групп основан на применении показателя сред-него квадратического отклонения (σ). Если величина интервала равна 0,5σ, то совокуп-ность разбивается на 12 групп, а когда величина интервала равна 2/З σ и σ, то совокуп-ность делится, собственно, на 9 и 6 групп. Однако при определении групп данными мето-дами существует большая вероятность получения «пустых» или малочисленных групп, характеристики изучаемого явления на основе которых будут недостаточно типичными для выделенной группы и изучаемой совокупности в целом.
Когда определено число групп, то следует определить интервалы группировки.
Интервал - это значения варьирующего признака, лежащие в определенных гра-ницах. Каждый интервал имеет верхнюю и нижнюю границы или одну из них. Нижней границей интервала называется наименьшее значение признака в интервале. Верхней границей интервала называется наибольшее значение признака в интервале. Величина интервала представляет собой разность между верхней и нижней границами интервала.
Интервалы группировки бывают:
Равные и неравные;
Открытые и закрытые.
В зависимости от величины интервалы группировки бывают: равные и неравные. В свою очередь, неравные интервалы подразделяются на прогрессивно возрастающие, про-грессивно убывающие, произвольные и специализированные.
Равные интервалы применяются в случае, если изменение количественного при-знака внутри изучаемой совокупности единиц наблюдения происходит равномерно и его вариация проявляется в сравнительно узких границах.
Ширина равного интервала определяется по следующей формуле:
h = R/n = Xmax - Xmin/n (3.2)
Xmax, Xmin - максимальное и минимальное значения признака в совокупности;
n - число групп.
Если максимальные или минимальные значения сильно отличаются от смежных с ними значений вариантов в упорядоченном ряду значений группировочного признака, то для определения величины интервала следует использовать не максимальное или мини-мальное значения, а значения, несколько превышающие минимум, и несколько меньше, чем максимум.
Полученную по формуле (3.2) величину округляют и она будет являться шириной интервала.
Существуют следующие правила определения ширины интервала.
Если величина интервала, рассчитанная по формуле (3.2) представляет собой вели-чину, которая имеет один знак до запятой (например: 0,67; 1,487; 3,82), то в этом случае полученные значения целесообразно округлить до десятых и их использовать в качестве ширины интервала. В приведенном выше примере это будут соответственно значения: 0,7; 1,5; 3,8.
Если рассчитанная величина интервала имеет две значащие цифры до запятой и несколько после запятой (например 14,876), то это значение необходимо округлить до це-лого числа (до 15).
В случае, когда рассчитанная величина интервала представляет собой трехзначное, четырехзначное и так далее число, то эту величину следует округлить до ближайшего числа, кратного 100 или 50. Например, 652 следует округлить до 650 или до 700.
Если размах вариации признака в совокупности велик и значения признака варьи-руют неравномерно, то надо использовать группировку с неравными интервалами. Нерав-ные интервалы могут быть получены в процессе объединения пустых, не содержащих ни одной единицы совокупности, равных интервалов. Это происходит в том случае, если по-сле построения равных интервалов по изучаемому признаку образуются группы, содер-жащие мало или не содержащие вообще ни одной единицы, т.е. группы, не отражающие определенных типов изучаемого явления по признаку. В этом случае возникает необхо-димость в увеличении интервалов группировки.
Также неравные интервалы могут быть прогрессивно-возрастающие или прогрес-сивно-убывающие в арифметической или геометрической прогрессии. Величина интерва-лов, изменяющихся в арифметической и геометрической прогрессии, определяется сле-дующим образом:
h i+1 = h i + a,
а в геометрической прогрессии:
h i+1 = h i x q,
а - константа: для прогрессивно-возрастающих интервалов имеет знак «+», а при прогрессивно-убывающих - знак «-».
q - константа: для прогрессивно-возрастающих - больше «1»; для прогрессивно-убывающих - меньше «1».
Применение неравных интервалов обусловлено тем, что в первых группах неболь-шая разница в показателях имеет большое значение, а в последних группах эта разница не существенна.
Например, при построении группировки строительных компаний города по показа-телю численности работающих, который варьирует от 500 человек до 3500 человек, неце-лесообразно рассматривать равные интервалы, т. к. учитываются как малые, так и круп-нейшие строительные фирмы города. Поэтому следует образовывать неравные интервалы: 500-1000, 1000-2000, 2000-3500, т. е. величина каждого последующего интервала больше предыдущего на 500 человек и увеличивается в арифметической прогрессии.
Выбор ис-следователя в построении равных или неравных интервалов зависит от степени заполне-ния каждой выделенной группы, т.е. от числа единиц в них. Если величина интервала су-щественна и содержит большое число единиц совокупности, то эти интервалы необходимо дробить, а в противном случае - объединять.
Интервалы группировок могут быть закрытыми и открытыми.
Закрытыми называются интервалы, у которых имеются обе границы: верхняя и нижняя границы.
Открытые - это интервалы, у которых указана только одна граница: как правило, верхняя - у первого интервала и нижняя - у последнего. Например, группы страховых компаний по числу работающих в них сотрудников (чел.): до 50, 50-100, 100-150, 150 и более. Применение открытых интервалов целесообразно в тех случаях, когда в совокупно-сти встречается незначительное число единиц наблюдения с очень малыми или очень большими значениями вариантов, которые резко, в несколько раз, отличаются от всех ос-тальных значений изучаемого признака.
При группировке единиц совокупности по количественному признаку границы ин-тервалов могут быть обозначены по-разному, в зависимости от того, непрерывный или дискретный признак положен в основание группировки.
Если основанием группировки служит непрерывный признак (например, группы строительных фирм по объему строительно-монтажных работ, выполненных собственны-ми силами (тыс. руб.): 1200-1400, 1400-1600, 1600-1800, 1800-2000), то одно ито же зна-чение признака выступает и верхней и нижней границами двух смежных интервалов. В данном случае объем работ 1400 тыс. руб. составляет верхнюю границу первого интервала и нижнюю границу второго, 1600 тыс. руб. - соответственно второго и третьего и т.д., т.е. верхняя граница i - го интервала равна нижней границе (i+1) - го интервала.
При таком обозначении границ может возникнуть вопрос, в какую группу вклю-чать единицы наблюдения, значения признака у которых совпадают с границами интерва-лов. Например, во вторую или третью группу должна войти строительная фирма с объе-мом строительно-монтажных работ 1600 тыс. рублей? Если верхняя граница формируется по принципу «исключительно», то фирма должна быть отнесена к третьей группе, в про-тивном случае - ко второй.
Для того, чтобы правильно отнести к той или иной группе единицу совокупности, значение признака которой совпадает с границами интервалов, можно ориентироваться на открытые интервалы (по нашему примеру группы строитель-ных фирм по объему строительно-монтажных работ преобразуются в следующие: до 1400, 1400-1600, 1600-1800, 1800 и более). В данном случае, вопрос отнесения отдельных еди-ниц совокупности, значения которых являются граничными, к той или иной группе реша-ется на основе анализа последнего открытого интервала.
Возможны два случая обозначе-ния последнего открытого интервала: 1) 1800 тыс. руб. и более; 2) более 1800 тыс. руб. В первом случае, строительные фирмы с объемом строительно-монтажных работ 1600 тыс. руб. попадут в третью группу; во втором случае - во вторую группу.
Если в основании группировки лежит дискретный признак, то нижняя граница i-ro интервала равна верхней границе i-1-го интервала, увеличенной на 1. Например, группы строительных фирм по числу занятого персонала (чел.) будут иметь вид: 100-150, 151-200, 201-300.
При определении границ интервалов статистических группировок иногда исходят из того, что изменение количественного признака приводит к появлению нового качества. В этом случае граница интервала устанавливается там, где происходит переход от одного качества к другому.
Строя такую группировку, следует дифференцированно устанавливать границы ин-тервалов для разных отраслей народного хозяйства. Это достигается путем использования группировок со специализированными интервалами.
Специализированные интерва-лы - это такие интервалы, которые применяются для выделения из совокупности одних и тех же типов по одному и тому же признаку для явлений, находящихся в различных усло-виях.
При изучении социально-экономических явлений на макроуровне часто применяют группировки, интервалы которых не будут ни прогрессивно-возрастающими, ни прогрес-сивно-убывающими. Такие интервалы называются произвольнымии , как правило, ис-пользуются при группировке предприятий, например, по уровню рентабельности.
10. Виды группировок
В зависимости от степени сложности изучаемого явления и от поставленных задач статистические группировки могут выполняться по одному или нескольким группировочным признакам.
Группировка называется простой (одномерной) , если однородные группы формируются по одному признаку одновременно.
Если однородные группы образуются по двум и более признакам, то группировка называется сложной.
В классе одномерных группировок выделяют следующие типы:
структурные – предназначены для выявления состава изучаемого явления;
типологические – предназначены для выделения в статистической совокупности различных социально-экономических типов явлений;
аналитические (факторные) – используются для изучения связей и зависимости между варьирующими признаками.
Структурные группировки
Структурные группировки используются для изучения внутреннего строения статистической совокупности и характеристики структурных сдвигов. Они дают информацию о текущем состоянии массовых явлений и применяются в целях оперативного управления.
Структурная группировка выполняется в несколько этапов:
выбор группировочного признака;
определение необходимого числа групп;
определение параметров групп;
распределение единиц наблюдения по выделенным группам;
расчет структурных характеристик;
формулировка выводов.
Выбор группировочного признака осуществляется в соответствии с целями статистического исследования. В качестве группировочного обычно выступает существенный признак. Обязательным условием выполнения любой группировки, в том числе и структурной является упорядочение статистической совокупности по значениям группировочного признака.
Определение необходимого числа групп . Число групп должно быть достаточным для объективного представления изучаемой совокупности. При большом числе групп различия между ними становятся малозаметными, а в самих группах в виду их малой наполняемости перестает действовать закон больших чисел и возможно проявления случайности. При малом же их числе в одну группу могут попасть статистические единицы с существенно различающимися значениями признака.
На количество выделяемых групп влияют следующие факторы:
уровень колеблемости группировочного признак - чем значительнее вариация признака, тем большее количество групп необходимо выделять при прочих равных условиях;
размер изучаемой статистической совокупности - чем больше размер исследуемой совокупности, тем большее количество групп необходимо выделять.
Выделенные группы должны быть достаточно заполненными. Наличие пустых групп или малое число статистических единиц в них свидетельствуют о неправильном определении их числа.
Ориентировочно число групп можно определить использую эмпирическую зависимость, называемую формулой Стерджесса:
m ≈ 1 + 3,322 × lg N ,
где m – количество групп;
N - число единиц статистической совокупности.
Зависимость Стерджесса дает хорошие результаты, если совокупность состоит из большого числа единиц, распределение близкое к нормальному, и при этом используются равные интервалы.
Существует еще один способ определения количества выделяемых групп, он связан с применением среднеквадратичного отклонения равными и неравными σ : если ширина интервала равна 0,5σ , то выделяется 12 групп, если 2/3σ ,то 9 групп, если σ – то 6 групп.
В каждой выделенной группе рассчитываются следующие параметры:
верхняя граница интервала x i в
нижняя граница интервала x i н
ширина интервала а i ;
середина интервала b i .
Нижней границей интервала x i н называется наименьшее значение признака в группе.
Верхней границей интервала x i в называется наибольшее значение признака в группе.
Интервалы группировки бывают равными и неравными (прогрессивно возрастающими, прогрессивно убывающими, произвольными, специализированными).
Если вариация признака проявляется в сравнительно узких границах, и распределение статистических единиц носит достаточно равномерный характер, то строят группировку с равными интервалами.
Для равноинтервальной группировки ширина интервала а i определяется по формуле:
а i = (X max – X min ) / m = R / m
где R – размах вариации,
R = X max - X min
При определении размаха вариации R из наблюдения исключаются аномальные значения признака. Полученное значение ширины интервала а i округляется в бóльшую сторону. На основе рассчитанной ширины интервала а i последовательно определяется границы интервалов x i н и x i в .
Определение границ начинается с первой группы. Ее нижняя граница принимается равной минимальному значению признака в совокупности, т. е. х 1 н =х min , верхняя граница определяется как x 1 в = х 1 н + а i
Для второй группы нижняя граница принимается равной верхней границе первой группы, т. е. x 2 н =х 1 в , верхняя определяется как x 2 в = х 2 н + а i и так далее.
В целом границы интервалов определяются формулами:
x i н = x i -1 в .
x i в = x i н + а i
Середина интервала (центральная варианта) b i определяется как полусумма верхней и нижней границ, т.е. по формуле:
b i = ( x i в + x i в )/2
Параметр середина интервала используется при расчете обобщающих характеристик изучаемой совокупности. Достаточно часто при выполнении группировки используются открытые интервалы. В открытых интервалах указывается только одна граница: верхняя - у последнего интервала, нижняя – у первого.
Для закрытия таких интервалов необходимо предварительно определить их ширину. Проблема ширины открытых интервалов решается следующим образом:
при равноинтервальной группировке она есть величина постоянная;
при неравноинтервальной - предварительно определяется закономерность изменения ширины интервала для некрайних групп, выявленная закономерность позволяет определить ширину соответствующего интервала и рассчитать недостающую границу.
Распределение единиц совокупности по группам.
Основной задачей данного этапа является подсчет числа единиц, попавших в каждую из выделенных групп n i .
При распределении единиц наблюдения по выделенным группам, особенно если группировочный признак является непрерывным, имеет место неопределенность: к какой группе относить единицы со значениями признака, совпадающими с границами интервалов? Для устранения неопределенности используют принцип единообразия – такие единицы включаются в группу, в которой нижняя граница совпадает со значением признака.
Например , имеются группы предприятий по объему производства, млн. руб.: 400 – 450; 450 – 500; 500 – 550; 550 – 600; 600 – 650.
К какой группе следует отнести предприятия с объемом производства 500млн. руб.? В соответствии с принципом единообразия - ко второй группе.
Расчет структурных характеристик.
Расчет заключается в определении для каждой группы удельного веса (доли) ее единиц в общем объеме статистической совокупности. Как и любая относительная величина этот показатель может быть определен в виде коэффициентов:
d i = n i / N
или в виде процентов
d i = ( n i / N ) ×100%
Рассчитав такие доли для всех групп, мы получаем структуру изучаемой статистической совокупности, равную полному набору долей, т.е. сумма d i = 1
или
сумма d i = 100%
На основе анализа показателей структуры делаются соответствующие выводы.
Формулировка выводов о составе совокупности
Для структурных группировок в выводах отражаются два положения:
Какие значения признака встречаются в совокупности наиболее часто, какие наиболее редко.
Каков характер изменения структуры в зависимости от изменения значения признака. С увеличением x доля может увеличиваться, либо уменьшаться. Это довольно типично для экономических показателей.
Выводы должны быть сделаны обязательно, иначе пропадает смысл группировки. Данные структурных группировок обычно представляются в форме соответствующей таблицы.
Типологическая группировка
Ее цель состоит в изучении распространенности различных типов экономических явлений в статистической совокупности. Типологические группировки применяются, как правило, к неоднородной совокупности и осуществляются посредством сложных неравноинтервальных группировок.
Результатом типологических группировок является разделение совокупности на классы, социально- экономические типы, однородные группы единиц.
По своей сути типологическая группировка представляет собой группировку-классификатор. Такие группировки часто основываются на устойчивом перечне групп, не меняющихся или меняющихся незначительно во времени.
Примером такой группировки является группировка предприятий по форме собственности (государственная, муниципальная, частная, смешанная) или группировка секторов экономики.
При выполнении типологических группировок важно правильно выбрать основание группировки. Для этого необходимо предварительно выявить возможные типы явления на основе анализа сущности и закономерностей его развития. Число групп и их параметры устанавливаются неформально на основе выделенных качественных закономерностей, часто с привлечением количественных признаков.
Аналитические группировки предназначены для выявления связи между изучаемыми признаками. Они позволяют выявить наличие и направление связи, а также измерить ее тесноту и силу.
Все исследуемые признаки в этом случае делятся на две группы:
факторные
результативные.
Взаимосвязь между ними проявляется в том, что с изменением среднего значения факторного признака систематически изменяется среднее значение результативного признака.
Сложные группировки
К сложным группировкам относятся группировки, выполняемые по двум и более основаниям. Сложные группировки делятся на-
комбинационные
многомерные.
Комбинационные группировки выполнятся по нескольким признакам последовательно. Последовательность устанавливается исходя из логики взаимосвязи показателей. Как правило, группировку начинают с атрибутивного признака. При комбинационной группировке совокупность логически последовательно разбивается на однородные части по отдельным признакам: на группы - по одному признаку, затем внутри каждой группы по второму признаку - на подгруппы и т.д. Такие группировки предназначены для более глубокого анализа изучаемого явления, позволяют выявить и сравнить различия и связи между исследуемыми признаками, которые невозможно установить на основе изолированных группировок по каждому из исследуемых признаков. Однако следует иметь в виду, что при изучении влияния большого числа признаков применение комбинационных группировок невозможно, так как это приводит к дроблению информации, а значит, к затушевыванию проявлений закономерности. Даже при наличии больших объемов информации приходится ограничиваться двумя – четырьмя признаками.
Комбинационная группировка по двум признакам (X, Y ) оформляется в виде шахматной таблицы, в которой значения одного признака X откладываются по строкам, а значения второго признака Y – по столбцам. На пересечении j –ого столбца и i -ой строки (в теле таблицы) находятся частоты совместного проявления значения признака Y в j- ом столбце и значения признака X в i -ой строке.
К многомерным группировкам относятся группировки, выполненные по нескольким группировочным признакам одновременно.
Цель многомерных группировок – классификация данных на основе множества признаков, то есть выделение групп статистических единиц, однородных по нескольким признакам одновременно.
В процессе такой группировки решаются, например, задачи типизации – выделяются самостоятельные экономические или социальные типы явлений.
Так, приемами многомерной классификации можно всю совокупность промышленных предприятий разбить на «мелкие», «средние» и «крупные», используя следующие признаки: численность промышленно- производственного персонала, объем продукции, стоимость ОПФ, потребление материальных ресурсов и т.д. Можно выделить типы предприятий по финансовому положению на основе таких показателей как размер прибыли, уровень рентабельности производства, уровень капитализации, уровень ликвидности ценных бумаг и т.д.
В психологии многомерные группировки используются для выделения типов людей по степени их профессиональной пригодности, в медицине – для диагностики болезней на основе множества симптомов.
При выполнении многомерных группировок могут быть использованы два основных подхода:
Первый заключается в том, что рассчитывается обобщающий показатель по совокупности группировочных признаков и проводится простая группировка по этому обобщающему показателю.
Второй подход состоит в использовании методом кластерного анализа.
Дисперсионный анализ есть совокупность статистических методов, предназначенных для проверки гипотез о связи между определенными признаками и исследуемыми факторами, которые не имеют количественного описания, а также для установления степени влияния факторов и их взаимодействия. В специальной литературе его часто называют ANOVA (от англоязычного названия Analysis of Variations). Впервые этот метод был разработан Р. Фишером в 1925 г.
Виды и критерии дисперсионного анализа
Этот метод используется для исследования связи между качественными (номинальными) признаками и количественной (непрерывной) переменной. По сути, он осуществляет тестирование гипотезы о равенстве средних арифметических нескольких выборок. Таким образом, его можно рассматривать как параметрический критерий для сравнения центров сразу нескольких выборок. Если использовать этот метод для двух выборок, то результаты дисперсионного анализа будут идентичны результатам t-критерия Стьюдента. Однако, в отличие от других критериев, это исследование позволяет изучить проблему более детально.
Дисперсионный анализ в статистике базируется на законе: сумма квадратов отклонений объединенной выборки равна сумме квадратов внутригрупповых отклонений и сумме квадратов межгрупповых отклонений. Для исследования используется критерий Фишера для установления значимости различия межгрупповых дисперсий от внутригрупповых. Однако для этого необходимыми предпосылками являются нормальность распределения и гомоскедастичность (равенство дисперсий) выборок. Различают одномерный (однофакторный) дисперсионный анализ и многомерный (многофакторный). Первый рассматривает зависимость исследуемой величины от одного признака, второй - сразу от многих, а также позволяет выявить связь между ними.
Факторы
Факторами называют контролируемые обстоятельства, что влияют на конечный результат. Его уровнем или способом обработки называют значение, которое характеризует конкретное проявление этого условия. Эти цифры обычно подают в номинальной или порядковой шкале измерений. Часто выходные значения измеряют в количественных или порядковых шкалах. Тогда возникает проблема группировки выходных данных в ряде наблюдений, что соответствуют примерно одинаковым числовым значениям. Если количество групп взять чрезмерно большим, то количество наблюдений в них может оказаться недостаточным для получения надежных результатов. Если брать число чрезмерно малым, это может привести к потере существенных особенностей влияния на систему. Конкретный способ группировки данных зависит от объема и характера варьирования значений. Количество и размеры интервалов при однофакторном анализе чаще всего определяют по принципу равных промежутков или по принципу равных частот.
Задачи дисперсионного анализа
Итак, существуют случаи, когда нужно сравнить две или больше выборок. Именно тогда и целесообразно применение дисперсионного анализа. Название метода указывает на то, что выводы делают на основе исследования составляющих дисперсии. Суть изучения состоит в том, что общее изменение показателя разбивают на составляющие части, которые соответствуют действию каждого отдельно взятого фактора. Рассмотрим ряд задач, которые решает типичный дисперсионный анализ.
Пример 1
В цехе есть ряд станков - автоматов, которые изготавливают определенную деталь. Размер каждой детали - это случайная величина, которая зависит от настройки каждого станка и случайных отклонений, возникающих в процессе изготовления деталей. Нужно по данным измерений размеров деталей определить, одинаково ли настроены станки.

Пример 2
Во время изготовления электрического аппарата используют различные типы изоляционной бумаги: конденсаторную, электротехническую и др. Аппарат можно пропитать различными веществами: эпоксидной смолой, лаком, смолой МЛ-2 и др. Утечки можно устранять под вакуумом при повышенном давлении, при нагреве. Пропитывать можно методом погружения в лак, под непрерывной струей лака и т. п. Электрический аппарат в целом заливают определенным компаундом, вариантов которого есть несколько. Показателями качества являются электрическая прочность изоляции, температура перегрева обмотки в рабочем режиме и ряд других. Во время отработки технологического процесса изготовления аппаратов надо определить, как влияет каждый из перечисленных факторов на показатели аппарата.
Пример 3
Троллейбусное депо обслуживает несколько троллейбусных маршрутов. На них работают троллейбусы различных типов, и оплату за проезд собирают 125 контролеров. Руководство депо интересует вопрос: как сравнить экономические показатели работы каждого контролера (выручку) учитывая различные маршруты, различные типы троллейбусов? Как определить экономическую целесообразность выпуска троллейбусов определенного типа на тот или другой маршрут? Как установить обоснованные требования к величине выручки, которую приносит кондуктор, на каждом маршруте в различных типах троллейбусов?
Задача по выбору метода состоит в том, как получить максимум информации относительно влияния на конечный результат каждого фактора, определить числовые характеристики такого влияния, их надежность при минимальных затратах и за максимально короткое время. Решить такие задачи позволяют методы дисперсионного анализа.
Однофакторный анализ
Исследование своей целью ставит оценку величины влияния конкретного случая на анализируемый отзыв. Другой задачей однофакторного анализа может быть сравнение двух или нескольких обстоятельств друг с другом с целью определения разницы их влияния на отзыв. Если нулевую гипотезу отвергают, то следующим этапом будет количественное оценивание и построение доверительных интервалов для полученных характеристик. В случае, когда нулевая гипотеза не может быть отброшенной, обычно ее принимают и делают вывод о сущности влияния.
Однофакторный дисперсионный анализ может стать непараметрическим аналогом рангового метода Краскела-Уоллиса. Он разработан американскими математиком Уильямом Краскелом и экономистом Вильсоном Уоллисом в 1952 г. Этот критерий назначен для проверки нулевой гипотезы о равенстве эффектов влияния на исследуемые выборки с неизвестными, но равными средними величинами. При этом количество выборок должно быть больше двух.

Критерий Джонкхиера (Джонкхиера-Терпстра) был предложен независимо друг от друга нидерландским математиком Т. Дж. Терпстром в 1952 г. и британским психологом Е. Р. Джонкхиером в 1954 г. Его применяют тогда, когда заранее известно, что имеющиеся группы результатов упорядочены по росту влияния исследуемого фактора, который измеряют в порядковой шкале.
М - критерий Бартлетта, предложенный британским статистиком Маурисом Стивенсоном Бартлеттом в 1937 г., применяют для проверки нулевой гипотезы о равенстве дисперсий нескольких нормальных генеральных совокупностей, с которых взяты исследуемые выборки, в общем случае имеющие различные объемы (число каждой выборки должно быть не меньше четырех).
G - критерий Кохрена, который открыл американец Вильям Геммел Кохрен в 1941 г. Его используют для проверки нулевой гипотезы о равенстве дисперсий нормальных генеральных совокупностей по независимым выборкам равного объема.
Непараметрический критерий Левене, предложенный американским математиком Ховардом Левене в 1960 г., является альтернативой критерия Бартлетта в условиях, когда нет уверенности в том, что исследуемые выборки подчиняются нормальному распределению.
В 1974 г. американские статистики Мортон Б. Браун и Алан Б. Форсайт предложили тест (критерий Брауна-Форсайта), который несколько отличается от критерия Левене.
Двухфакторный анализ
Двухфакторный дисперсионный анализ применяют для связанных нормально распределенных выборок. На практике часто используют и сложные таблицы этого метода, в частности те, в которых каждая ячейка содержит набор данных (повторные измерения), соответствующих фиксированным значениям уровней. Если предположения, необходимые для применения двухфакторного дисперсионного анализа, не выполняются, то используют непараметрический ранговый критерий Фридмана (Фридмана, Кендалла и Смита), разработанный американским экономистом Милтоном Фридманом в конце 1930 г. Этот критерий не зависит от типа распределения.
Предполагается только, что распределение величин является одинаковым и непрерывным, а сами они независимы одна от другой. При проверке нулевой гипотезы выходные данные подают в форме прямоугольной матрицы, в которой строки соответствуют уровням фактора В, а столбцы - уровням А. Каждая ячейка таблицы (блока) может быть результатом измерений параметров на одном объекте или на группе объектов при постоянных значениях уровней обоих факторов. В этом случае соответствующие данные подают как средние значения определенного параметра по всем измерениям или объектам исследуемой выборки. Для применения критерия выходных данных необходимо перейти от непосредственных результатов измерений к их рангу. Ранжирование осуществляют по каждой строке отдельно, то есть величины упорядочивают для каждого фиксированного значения.

Критерий Пейджа (L-критерий), предложенный американским статистиком Е. Б. Пейджем в 1963 г., предназначен для проверки нулевой гипотезы. Для больших выборок применяют аппроксимацию Пейджа. Они при условии реальности соответствующих нулевых гипотез подчиняются стандартному нормальному распределению. В случае, когда в строках исходной таблицы есть одинаковые значения, необходимо использовать средние ранги. При этом точность выводов будет тем хуже, чем больше будет количеств таких совпадений.
Q - критерий Кохрена, предложенный В. Кохреном в 1937 г. Его используют в случаях, когда группы однородных субъектов подвергаются воздействиям, количество которых превышает два и для которых возможны два варианта отзывов - условно-отрицательный (0) и условно-положительный (1). Нулевая гипотеза состоит из равенства эффектов влияния. Двухфакторный дисперсионный анализ дает возможность определить существование эффектов обработки, однако не дает возможности установить, для каких именно столбцов существует этот эффект. При решении данной проблемы применяют метод множественных уравнений Шеффе для связанных выборок.
Многофакторный анализ
Задача многофакторного дисперсионного анализа возникает тогда, когда нужно определить влияние двух или большего количества условий на определенную случайную величину. Исследование предусматривает наличие одной зависимой случайной величины, измеренной в шкале разницы или отношений, и нескольких независимых величин, каждая из которых выражена в шкале наименований или в ранговой. Дисперсионный анализ данных является достаточно развитым разделом математической статистики, который имеет массу вариантов. Концепция исследования общая как для однофакторного, так и для многофакторного. Сущность ее состоит в том, что общую дисперсию разбивают на составляющие, что соответствует определенной группировке данных. Каждой группировке данных соответствует своя модель. Здесь мы рассмотрим только основные положения, нужные для понимания и практического использования наиболее применяемых его вариантов.

Дисперсионный анализ факторов требует достаточно внимательного отношения к сбору и подаче входных данных, а особенно к интерпретации результатов. В отличие от однофакторного, результаты которого можно условно разместить в определенной последовательности, результаты двухфакторного требуют более сложного представления. Еще сложнее ситуация возникает, когда есть три, четыре или больше обстоятельств. Из-за этого в модель достаточно редко включают больше трех (четырех) условий. Примером может быть возникновение резонанса при определенной величине емкости и индуктивности электрического круга; проявление химической реакции при определенной совокупности элементов, из которых построена система; возникновение аномальных эффектов в сложных системах при определенном совпадении обстоятельств. Наличие взаимодействия может в корне изменить модель системы и иногда привести к переосмыслению природы явлений, с которыми имеет дело экспериментатор.
Многофакторный дисперсионный анализ с повторными опытами
Данные измерений достаточно часто можно группировать не по двум, а по большему количеству факторов. Так, если рассматривать дисперсионный анализ срока службы покрышек колес троллейбуса с учетом обстоятельств (завод-производитель и маршрут, на котором эксплуатируются покрышки), то можно выделить как отдельное условие сезон, во время которого эксплуатируются покрышки (а именно: зимняя и летняя эксплуатация). В результате будем иметь задачу трехфакторного метода.
При наличии большего количества условий подход такой же, как и в двухфакторном анализе. Во всех случаях модель пытаются упростить. Явление взаимодействия двух факторов проявляется не так часто, а тройное взаимодействие бывает только в исключительных случаях. Включают то взаимодействие, для которого есть предыдущая информация и серьезные основания, чтобы ее учесть в модели. Процесс выделения отдельных факторов и их учета относительно простой. Поэтому часто возникает желание выделить больше обстоятельств. Этим не следует увлекаться. Чем больше условий, тем менее надежной становится модель и тем больше вероятность ошибки. Сама модель, в которую входит большое количество независимых переменных, становится достаточно сложной для интерпретации и неудобной для практического использования.
Общая идея дисперсионного анализа
Дисперсионный анализ в статистике - это метод получения результатов наблюдений, зависимых от различных одновременно действующих обстоятельств, и оценки их влияния. Управляемую переменную величину, которая соответствует способу воздействия на объект исследования и в некоторый период времени приобретает определенное значение, называют фактором. Они могут быть качественными и количественными. Уровни количественных условий приобретают определенное значение на числовой шкале. Примерами являются температура, давление прессования, количество вещества. Качественные факторы - это разные вещества, разные технологические способы, аппараты, наполнители. Их уровням соответствует шкала наименований.

К качественным можно отнести также вид упаковочного материала, условия хранения лекарственной формы. Сюда же рационально отнести степень измельчения сырья, фракционный состав гранул, имеющих количественное значение, однако плохо поддающихся регулированию, если использовать количественную шкалу. Число качественных факторов зависит от вида лекарственной формы, а также физических и технологических свойств лекарственных веществ. Например, из кристаллических веществ можно получать таблетки прямым прессованием. В этом случае достаточно провести выбор скользящих и смазывающих веществ.
Примеры качественных факторов для различных видов лекарственных форм
- Настойки. Состав экстрагента, тип экстрактора, способ подготовки сырья, способ получения, способ фильтрации.
- Экстракты (жидкие, густые, сухие). Состав экстрагента, способ экстракции, тип установки, способ удаления экстрагента и балластных веществ.
- Таблетки. Состав вспомогательных веществ, наполнители, разрыхлители, связующие, смазывающие и скользящие вещества. Способ получения таблеток, вид технологического оборудования. Вид оболочки и ее компонентов, пленкообразователи, пигменты, красители, пластификаторы, растворители.
- Инъекционные растворы. Вид растворителя, способ фильтрации, природа стабилизаторов и консервантов, условия стерилизации, способ заполнения ампул.
- Суппозитории. Состав суппозиторной основы, способ получения суппозиториев, наполнителей, упаковки.
- Мази. Состав основы, структурные компоненты, способ приготовления мази, вид оборудования, упаковка.
- Капсулы. Вид оболочечного материала, способ получения капсул, тип пластификатора, консерванта, красителя.
- Линименты. Способ получения, состав, тип оборудования, тип эмульгатора.
- Суспензии. Вид растворителя, вид стабилизатора, метод диспергирования.
Примеры качественных факторов и их уровней, изучаемых в процессе изготовления таблеток
- Разрыхлитель. Крахмал картофельный, глина белая, смесь натрия гидрокарбоната с кислотой лимонной, магния карбонат основной.
- Связывающий раствор. Вода, крахмальный клейстер, сахарный сироп, раствор метилцеллюлозы, раствор оксипропилметилцеллюлозы, раствор поливинилпирролидона, раствор поливинилового спирта.
- Скользящая вещество. Аэросил, крахмал, тальк.
- Наполнитель. Сахар, глюкоза, лактоза, натрия хлорид, фосфат кальция.
- Смазывающее вещество. Стеариновая кислота, полиэтиленгликоль, парафин.
Модели дисперсионного анализа в исследовании уровня конкурентоспособности государства
Одним из важнейших критериев оценки состояния государства, по которым проводится оценка уровня его благосостояния и социально-экономического развития, является конкурентоспособность, то есть совокупность свойств, присущих национальной экономике, которые определяют способность государства конкурировать с другими странами. Определив место и роль государства на мировом рынке, можно установить четкую стратегию обеспечения экономической безопасности в международных масштабах, ведь она является залогом положительных взаимоотношений России со всеми игроками мирового рынка: инвесторами, кредиторами, правительствами государств.
Для сравнения уровня конкурентоспособности государств проводится ранжирование стран с помощью комплексных индексов, которые включают различные взвешенные показатели. В основу этих индексов заложены ключевые факторы, влияющие на экономическое, политическое и т. п. положение. Комплекс моделей исследования конкурентоспособности государства предусматривает использование методов многомерного статистического анализа (в частности, это дисперсионный анализ (статистика), эконометрическое моделирование, принятие решений) и включает следующие основные этапы:
- Формирование системы показателей-индикаторов.
- Оценку и прогнозирование индикаторов конкурентоспособности государства.
- Сравнение показателей-индикаторов конкурентоспособности государств.
А теперь рассмотрим содержание моделей каждого из этапов данного комплекса.
На первом этапе с помощью методов экспертного изучения формируется обоснованный комплекс экономических показателей-индикаторов оценки конкурентоспособности государства с учетом специфики ее развития на основе международных рейтингов и данных статистических отделов, отражающих состояние системы в целом и ее процессов. Выбор этих показателей обоснован необходимостью отобрать те из них, которые наиболее полно с точки зрения практики позволяют определить уровень государства, его инвестиционную привлекательность и возможности относительной локализации существующих потенциальных и реально действующих угроз.

Основные показатели-индикаторы международных рейтинг-систем - это индексы:
- Глобальной конкурентоспособности (ИГК).
- Экономической свободы (ИЭС).
- Развития человеческого потенциала (ИРЧП).
- Восприятия коррупции (ИВК).
- Внутренних и внешних угроз (ИВЗЗ).
- Потенциала международного влияния (ИПМВ).
Второй этап предусматривает оценку и прогнозирование индикаторов конкурентоспособности государства по международным рейтингам для исследуемых 139 государств мира.
Третий этап предусматривает сравнение условий конкурентоспособности государств при помощи методов корреляционно-регрессионного анализа.
Используя результаты исследования можно определить характер протекания процессов в целом и по отдельным составляющим конкурентоспособности государства; проверить гипотезу о влиянии факторов и их взаимосвязи при соответствующем уровне значимости.
Реализация предложенного комплекса моделей позволит не только оценить сложившуюся ситуацию уровня конкурентоспособности и инвестиционной привлекательности государств, но и проанализировать недостатки управления, предупредить ошибки неправильных решений, не допустить развития кризиса в государстве.
Общие определения
Целью дисперсионного анализа (ANOVA – Analysis of Variation) является проверка значимости различия между средними в разных группах с помощью сравнения дисперсий этих групп. Разделение общей дисперсии на несколько источников (связанных с различными эффектами в плане), позволяет сравнить дисперсию, вызванную различием между группами, с дисперсией, вызванной внутригрупповой изменчивостью.
Проверяемая гипотеза состоит в том, что различия между группами нет. При истинности нулевой гипотезы, оценка дисперсии, связанной с внутригрупповой изменчивостью, должна быть близкой к оценке межгрупповой дисперсии. При ложности - значимо отклоняться.
В целом дисперсионный анализ может быть разделён на несколько видов:
одномерный (одна зависимая переменная) и многомерный (несколько зависимых переменных);
однофакторный (одна группирующая переменная) и многофакторный (несколько группирующих переменных) с возможным взаимодействием между факторами;
с простыми измерениями (зависимая переменная измеряется лишь один раз) и с повторными (зависимая переменная измеряется несколько раз).
В STATISITICA реализованы все известные модели дисперсионного анализа.
В STATISITICA дисперсионный анализ можно провести с помощью модуля Дисперсионный анализ в блоке STATISITICA Base (Анализ -> Дисперсионный анализ(ДА)) . Для построения модели специального вида используется полная версия Дисперсионного анализа, представленная в модулях Общие линейные модели , Обобщённые линейные и нелинейные модели , Общие регрессионные модели , Общие модели частных наименьших квадратов из блока Углубленные методы анализа (STATISTICA Advanced Linear/Non-Linear Models ).
в начало
Пошаговый пример в STATISTICA
Мы будем иллюстрировать возможности дисперсионного анализа в STATISITICA , рассматривая пошаговый модельный пример.
Исходный файл данных описывает совокупность людей с разным уровнем дохода, образования, возраста и пола. Рассмотрим, как влияют уровень образования, возраст и пол на уровень дохода.
По возрасту все люди были разделены на четыре группы:
до 30 лет;
от 31 до 40 лет;
от 41 до 50 лет;
от 51 года.
По уровню образования произошло деление на 5 групп:
незаконченное среднее;
среднее;
среднее профессиональное;
незаконченное высшее;
высшее.
Так как данные модельные, то полученные результаты будут носить в основном качественный характер и иллюстрировать способ проведения анализа.
Шаг 1. Выбор анализа
Выберем дисперсионный анализ из меню: Анализ -> Углубленные методы анализа -> Общие линейные модели .
Рис. 1. Выбор дисперсионного анализа из выпадающего меню STATISTICA
Далее откроется окно, в котором представлены различные виды анализа. Выбираем Вид анализа – Факторный Дисперсионный анализ .

Рис. 2. Выбор вида анализа
В этом окне также можете выбрать способ построения модели: диалоговый режим или использовать мастер анализа. Выберем диалоговый режим.
Шаг 2. Задание переменных
Из открытого файла данных выберем переменные для анализа, щелкните кнопку Переменные , выберете:
Доход – зависимая переменная,
Уровень образования , Пол и Возраст – категориальные факторы (предикторы).
Заметим, что Коды факторов в этом простом примере можно не задавать. При нажатии на кнопку OK , STATISTICA задаст их автоматически.

Рис. 3. Задание переменных
Шаг 3. Изменение опций
Обратимся к вкладке Опции в окне GLM Факторный ДА .

Рис. 4. Вкладка Опции
В этом диалоговом окне вы можете:
выбрать случайные факторы;
задать тип параметризации модели;
указать тип сумм квадратов (SS), имеется 6 различных сумм квадратов (SS);
включить проведение кросс-проверки.
Оставим все установки по умолчанию (этого достаточно в большинстве случаев) и нажмём кнопку ОК .
Шаг 4. Анализ результатов – просмотр всех эффектов
Результаты анализа можно посмотреть в окне Результаты с помощью вкладок и группы кнопок. Рассмотрим, например, вкладку Итоги .

Рис. 5. Окно анализа результатов: вкладка Итоги
С этой вкладки можно получить доступ ко всем основным результатам. Воспользуйтесь остальными вкладками для получения дополнительных результатов. Кнопка Меньше позволяет изменить диалоговое окно результатов, удалив вкладки, которые, как правило, не используются.
При нажатии кнопки Проверить все эффекты получаем следующую таблицу.

Рис. 6. Таблица всех эффектов
Эта таблица выводит основные результаты анализа: суммы квадратов, степени свободы, значения F-критерия, уровни значимости.
Для удобства исследования значимые эффекты (p<.05) выделены красным цветом. Два главных эффекта (Уровень образования и Возраст ) и некоторые взаимодействия в данном примере являются значимыми (p<.05).
Шаг 5. Анализ результатов – просмотр заданных эффектов
Чтобы посмотреть, каким образом средний уровень дохода различается по категориям, удобнее всего воспользоваться графическими средствами. При нажатии на кнопку Все эффекты/графики появится следующее диалоговое окно.

Рис. 7. Окно Таблица всех эффектов
В окне перечислены все рассматриваемые эффекты. Статистически значимые эффекты помечены *.
Например, выберем эффект Возраст , в группе Отображать укажем Таблицу и нажмём ОК . Появится таблица, в которой для каждого уровня эффекта приведено среднее значение зависимой переменной (Доход) , величина стандартной ошибки и границы доверительных пределов.

Рис. 8. Таблица с описательными статистиками по уровням переменной Возраст
Эту таблицу удобно представить в графическом виде. Для этого выберем График в группе Отображать диалогового окна Таблица всех эффектов и нажмём ОК . Появится соответствующий график.

Рис. 9. График зависимости среднего дохода от возраста
Из графика ясно видно, что между группами людей разного возраста есть разница в уровне дохода. Чем выше возраст, тем больше доход.
Аналогичные операции проведём для взаимодействия нескольких факторов. В диалоговом окне выберем Пол *Возраст и нажмём ОК .

Рис. 10. График зависимости среднего дохода от пола и возраста
Получен неожиданный результат: для опрошенных людей в возрасте до 50 лет уровень дохода растёт с возрастом и не зависит от пола; для опрошенных людей старше 50 лет женщины имеют значимо больший доход, чем мужчины.
Стоит построить полученный график в разрезе уровня образования. Возможно, такая закономерность нарушается в некоторых категориях или, наоборот, носит универсальный характер. Для этого выберем Уровень образования * Пол * Возраст и нажмём ОК .

Рис. 11. График зависимости среднего дохода от пола, возраста, уровня образования
Видим, что полученная зависимость не характерна для среднего и среднего профессионального образования. В остальных случаях она справедлива.
Шаг 6. Анализ результатов – оценка качества модели
Выше в основном использовались графические средства дисперсионного анализа. Рассмотрим некоторые другие полезные результаты, которые можно получить.
Во-первых, интересно посмотреть, какую долю изменчивости объясняют рассматриваемые факторы и их взаимодействия. Для этого во вкладке Итоги нажмём на кнопку Общая R модели . Появится следующая таблица.
Рис. 12. Таблица SS модели и SS остатков
Число в столбце Множеств. R2 – квадрат множественного коэффициента корреляции; оно показывает, какую долю изменчивости объясняет построенная модель. В нашем случае R2 = 0.195, что говорит о невысоком качестве модели. В самом деле, на уровень дохода влияют не только факторы, внесённые в модель.
Шаг 7. Анализ результатов – анализ контрастов
Часто требуется не только установить различие в среднем значении зависимой переменной для разных категорий, но и установить величину различия для заданных категорий. Для этого следует исследовать контрасты.
Выше было показано, что уровень дохода для мужчин и женщин значимо отличается для возраста от 51, в остальных случаях различие не значимо. Выведем разницу в уровне дохода для мужчин и женщин в возрасте выше 51 года и между 40 и 50 годами.
Для этого перейдём во вкладку Контрасты и выставим все значения следующим образом.

Рис. 13. Вкладка Контрасты
При нажатии кнопки Вычислить появится несколько таблиц. Нас интересует таблица с оценками контрастов.

Рис. 14. Таблица Оценки контрастов
Можно сделать следующие выводы:
для мужчин и женщин старше 51 года разница в уровне дохода составляет 48,7 тыс. долл. Разница значима;
для мужчин и женщин в возрасте от 41 до 50 лет разница в уровне дохода составляет 1,73 тыс. долл. Разница не значима.
Аналогично можно задать более сложные контрасты или воспользоваться одним из заранее заданных наборов.
Шаг 8. Дополнительные результаты
Используя остальные вкладки окна результатов можно получить следующие результаты:
средние значения зависимой переменной для выбранного эффекта – вкладка Средние ;
проверка апостериорных критериев (post hoc) – вкладка Апостериорные ;
проверка сделанных для проведения дисперсионного анализа предположений – вкладка Предположения ;
построение профилей отклика/желательности – вкладка Профили ;
анализ остатков – вкладка Остатки ;
вывод матриц, используемых в анализе – вкладка Матрицы ;
 Ударение в английском языке
Ударение в английском языке 10 слов с ударением на 1 слог
10 слов с ударением на 1 слог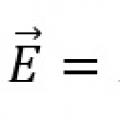 Закон Ома для замкнутой цепи и неоднородного участка цепи
Закон Ома для замкнутой цепи и неоднородного участка цепи